![[レポート]Amazon CloudWatch のログの価値を最大化する Byte to insight: Maximize value from your logs with Amazon CloudWatch (COP406)](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート]Amazon CloudWatch のログの価値を最大化する Byte to insight: Maximize value from your logs with Amazon CloudWatch (COP406)
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
本記事は「AWS re:Invent 2024 - Build real-time intelligent systems with InfluxDB (sponsored by InfluxData) | DAT101-S」のセッションレポートです。
セッション動画は以下で公開されています。
セッションのタイトルをみてビビッときました。(おもしろそうという意味で)
自分もCloudWatchのログを有効に活用できてるか?と問われると回答に詰まります。
もちろん、何かトラブルが起きた際はCloudWatch等のログを確認しますが、普段から有効利用できているかと言えば...
そこで、新機能含め、CloudWatchの色々な活用方法を紹介してくれる本セッションを聞いてみたので記事として残します。
概要
[概要]
Businesses often struggle with too many logs and not enough actionable insights. In this session, explore the full log data lifecycle, from ingestion to insights, and uncover concrete strategies to extract maximum value using the latest Amazon CloudWatch Logs capabilities. Learn practical techniques to optimize log data for cost-effectiveness and business impact. This isn't the CloudWatch of yesteryear—it's a transformed, customer-centric observability platform that can revolutionize how you manage and use log data.
[機械翻訳]
企業はしばしば、多すぎるログと実用的な洞察の不足に悩まされています。このセッションでは、取り込みから洞察に至るまで、ログデータのライフサイクル全体を探求し、Amazon CloudWatch Logsの最新機能を使用して最大の価値を引き出す具体的な戦略を明らかにします。費用対効果とビジネスインパクトのためにログデータを最適化する実践的なテクニックを学びます。これは、かつてのCloudWatchではありません。これは、ログデータの管理および使用方法に革命をもたらす、変革された顧客中心の観測可能性プラットフォームです。
自分なりに要約
みなさんはCloudWatchで取得しているログを活用できていますか?
このセッションではログの価値を最大化する方法を学びます。
価値の最大化とは、ただ単にコストを下げることではありません。
何が必要かを判断した上で、必要な部分のみにフォーカスを当てることでコストを含めたログ利用の効率をあげることが、ログの価値最大化に繋がります。
このセッションでは、実際によくある課題を例にして、CloudWatchの各機能でいかに解決していくか?ということを学んでいきます。
こんな人に見てほしい
- CloudWatchのログをもっと活用したい
- 実際にどんなケースでCloudWatchのどの機能を使えば効率がいいのか分からない
- コストを優先すべきログと、スピードと質を優先すべきログの例が知りたい
- CloudWatchの新機能がre:Invent前にいくつかローンチされていたが、どんな機能なのか追えていない
内容
はじめに
このセッションで得られるものは
- CloudWatchの新機能
- CloudWatchの機能を最大限に活用する方法
- 具体的なテクニック
ちなみにセッションではログの価値に関することをなん度も言うそうです。
もちろん大事なことだからです。
以下はアジェンダです。

CloudWatchとは?
まずはCloudWatchのログの価値云々を話す前にCloudWatchとはなんですか?という話です。
CloudWatchは下の図の中にあるものすべてです。
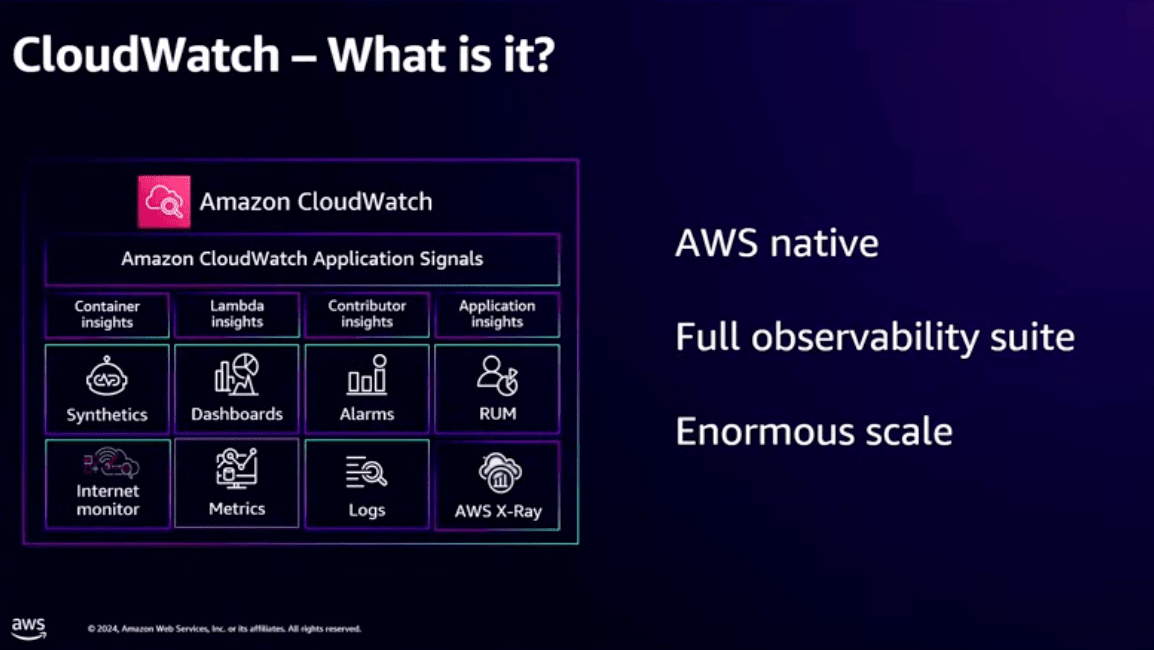
多いですね〜
スピーカーの方も言っていますが、CloudWatchは大規模なAWSネイティブのフルスタックオブザーバビリティソリューションです。
インフラ管理もアプリの起動も地域も関係ありません。
CloudWatchは派生した機能も多く、私も名前は聞いたことあるけど触ったことのない機能がいくつかあります。
CloudWatchの歴史
特に今回のセッションの主軸となるログに関連した歴史です。
2014~2022
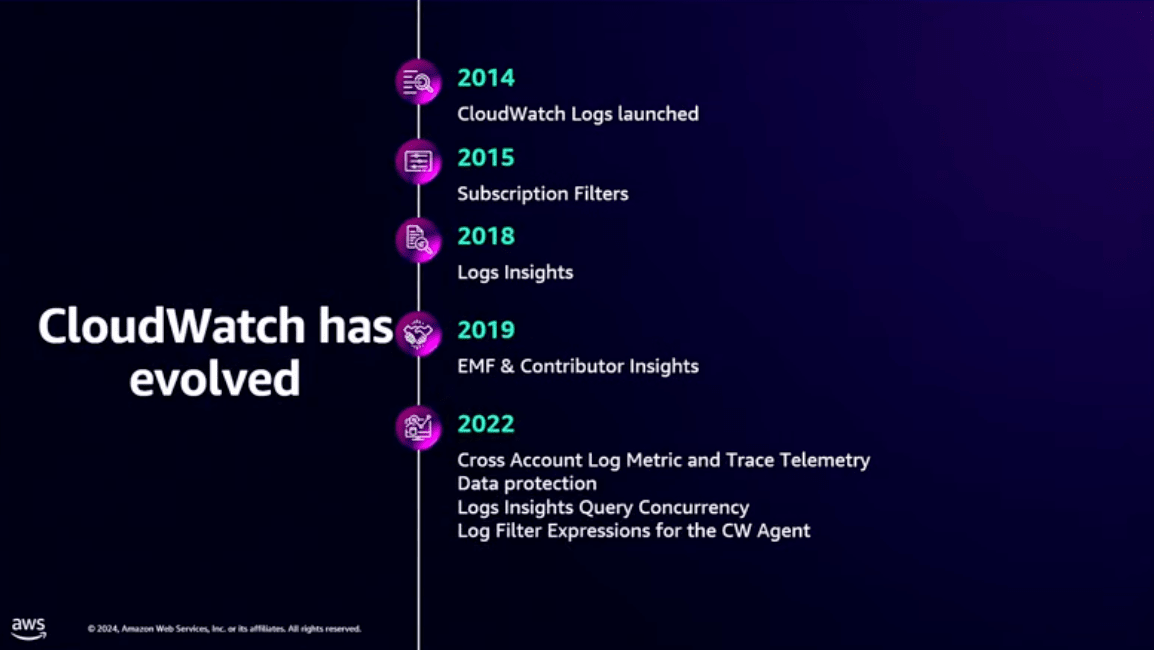
2014年にCloudWatchがリリースされました。
それから長年に渡りユーザーからの要望を受け取り、改善や機能追加が行われてきました。
2023~2024

過去数年の傾向として、CloudWatch内のログから価値を引き出すような変更や改善が多く加えられました。
このre:Invent前にもいくつか機能が追加されていましたね。
上の画像では、ここ最近の全てのアップデートを載せられてはいませんが、このセッションでできる限り伝えてくれるそうです。
最近発表されたAmazon Q Developerの運用調査機能についても、内部的にはCloudWatchが実行されており、AWSネイティブなオブザーバービリティプラットフォームとなっているようです。
おそらく新機能はこちらだと思います。
また、関連するセッションとしてこちらのレポートも参考になります。
セッションのゴール
新しい機能はたくさんありますが、このセッションではそれらのアップデート内容を細かく伝えるのではなく
ログを収取して使用する際に、どのようなアプローチで、何を記録すべきか?またどのように活用するのかを考える方法を理解するのがこのセッションのゴールのようです。
しかし、価値と言ってもいろいろ種類がありますよね。
もっとも価値があるのは、重要なデータからなんらかの洞察を得ることです。
そのためにはコストを考える必要があります。
とある疑問に対し、価値のある回答が得られるのであれば、コストは気にせず調査するべきです。
逆に、基本的な疑問などは、価値が低いため、なるべくコストを抑えることで価値が最大化できます。

上で書いたことは私の読解力が乏しく、ちょっと伝わりづらいかもしれませんが、言いたいことはとてもよくわかります。
今の時代であれば簡単なことはAIに任せてしまおうという流れもありますし、時間(コスト)はより価値の高い情報へかけるべきだと思います。
インサイトとは?
インサイトとはデータから得られる深い理解や気づきのことです。
つまり、質問に対する答えを導き出すものです。
下の文章はOxford Languagesに記載されているインサイトに関する説明です。

ここに書かれているように、インサイトとは
「人や物事に対する鋭く深い直感的な理解を得ること」です。
インサイトを得ることで、オブザーバビリティを高め、ログの価値を最大化することができます。
これによって、より良い意思決定が可能になります。
ログからインサイトを得るには
- ログから何を得たいのか?
- 得たい情報に必要なコンテキスト(文脈)
- 特定の時点でのイベントやアプリケーションの要素
が必要になります。
ちょっと難しいですね...
そこで、日常的に私たちが目にするようなもので例えてくれています。
以下の画像では、先ほどのログからインサイトを得るために必要な要素をいくつか例として表にまとめています。
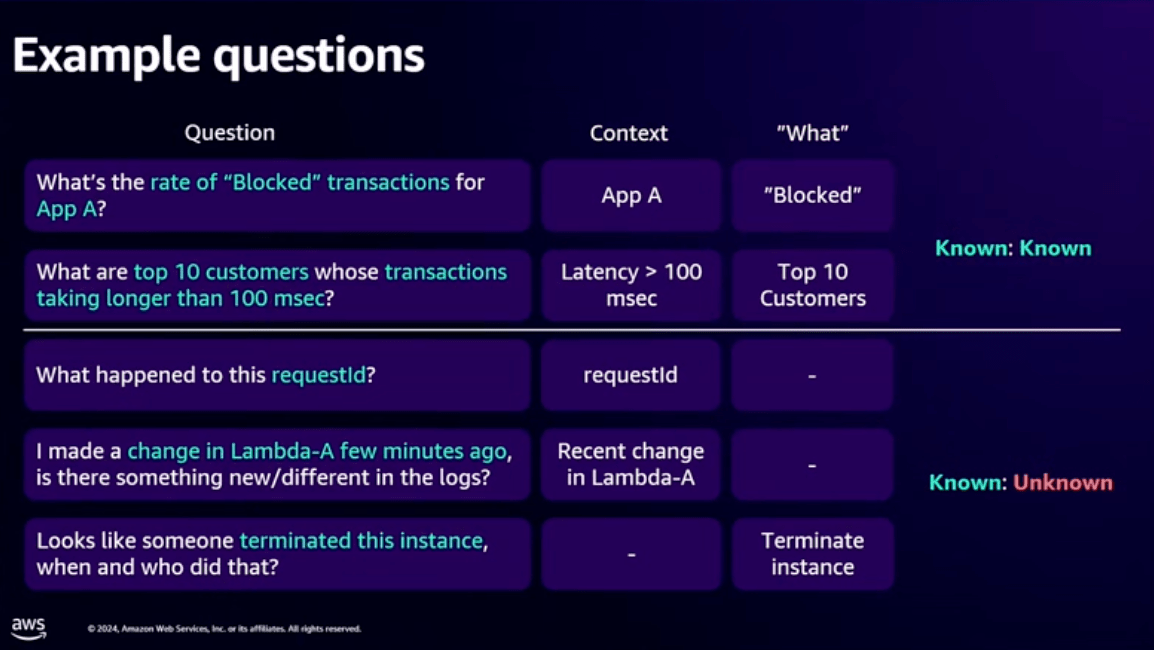
表の見方はこんな感じだと思われます。
~表の見方~
Question: 質問内容
Context: コンテキスト情報
What: 求めている情報の種類
Known/Unknown: 既知の情報 or 未知の情報
ContextとWhatが既知の情報であるかどうかが重要になります。
分かりやすいもので例を挙げると、
Question:レイテンシーが増加することで影響を受けるTOP10人の顧客は誰なのか?
Context: レイテンシが100ms以上
What: TOP10の顧客
Known:Known
この疑問はContextと、Whatがすでに分かっている状態(Known:Known)を表しています。
この場合、どんなに優れたツールを使っても、例えコストをかけたとしても、ログから得られる価値には限界があります。
例えば上の例だと、レイテンシが100ms以上のTOP10を表示すると、TOP10の顧客一覧は分かりますが、それ以上のことは分かりません。
つまり、Known:Knownの場合は、コストを可能な限り抑えて、必要なインサイトを得ることが、もっともログの価値を高めることにつながります。
逆に、どちらかの情報が欠けている場合(Known:UnKnown)は以下のようになります。
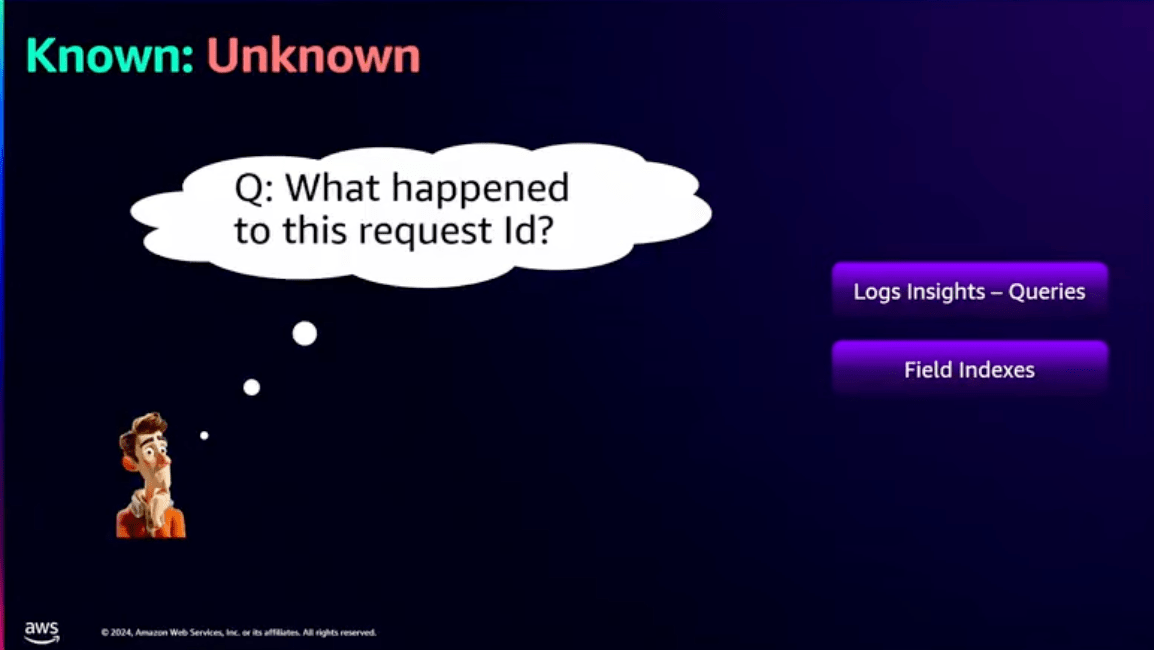
Question:このリクエストIDで何が起きてますか?
Context: リクエストID
What: 不明
Known:UnKnown
こちらはContextは分かっているけど、Whatが分からない状態(Known:UnKnown)です。
この場合は、コスト削減よりも素早く、かつ正確なインサイトを得ることが求められます。
上の例でいうと、一つのリクエストIDを調査するために、1クエリ2分で済むなら$10を追加で支払ってでも情報の正確さと、時間短縮にコストを割くべきという考え方です。
つまり、どこに重点を持っていくか?という話になります。
以下の図がそれを表していますね。

Known:Known
では、具体的にKnown:Knownの場合に、どのような機能を使うことで効率化できるのか考えてみましょう。

先ほどの例で、特定のアクションがBlockされてたリクエストや、レイテンシーが100msを超えるTOP10の顧客についての例がありました。
この問題に対応する際、ログを確認して特定しようとしますよね?
ちなみに私はしますね。

これを、仮に他の人とも共有したい場合、クエリを作ってダッシュボードを共有するやり方があります。
しかし、そのやり方の問題点は、同じクエリが何度も実行されてしまい、クエリ料金が馬鹿にならない金額になる可能性があります。
そこで、もっと効率的な方法でコスト削減したいですね。
メトリクスフィルタ
どうすればいいでしょうか?
アプリケーションAでリクエストがブロックされる割合を知りたいという例では、
ログから「actions=block」を探して、指定した期間内の5分間隔で、どれくらいblockが発生しているか知ればよさそうですね。

これにはメトリクスフィルタを使うと良いです。

メトリクスフィルタは、ロググループに特定の値をキャプチャするフィルタを設定できます。
メトリクスフィルタは以下の記事でも紹介されています。
例えば、blockが発生するたびにデータポイントをメトリクスに追加することで、何度もクエリを実行しなくてもblockのみを特定して状況を確認することができます。
これでコストをかけずに、必要な情報のみを得られる仕組みができます。
メトリクスフィルタは使ったことがある方も多いのではないでしょうか?
私もよくerrorが出た場合のみメトリクスフィルタでフィルタリングして、アラームを出すというようなことをよくやります。
欲しい情報が大量のログの中の一部だけ。というようなケースではよく使われているイメージです。
Embedded Metrics
他にもEmbedded Metrics(埋め込みメトリクス)という機能があります。

Embedded Metricsは先ほどのフィルタの次のステップで、ログに値を直接埋め込むことでCloudWatchが自動的にカスタムメトリクスを作成する機能です。
字面だけだと、ん?どういうこと?となりそうなので、以下のブログを見ていただくと分かりやすいかと思います。
こちらはフィルタの設定が不要でどのリージョンでも利用可能です。
アプリケーション開発時に、メトリクス収集のための設定を組み込んでおくことで、ログから自動的にメトリクスを生成できます。
Contributor Insights
次に、レイテンシが10ms以上かかっている顧客トップ10は?という質問に対するアプローチです。
こちらはContributor Insightsを使うと効率的です。
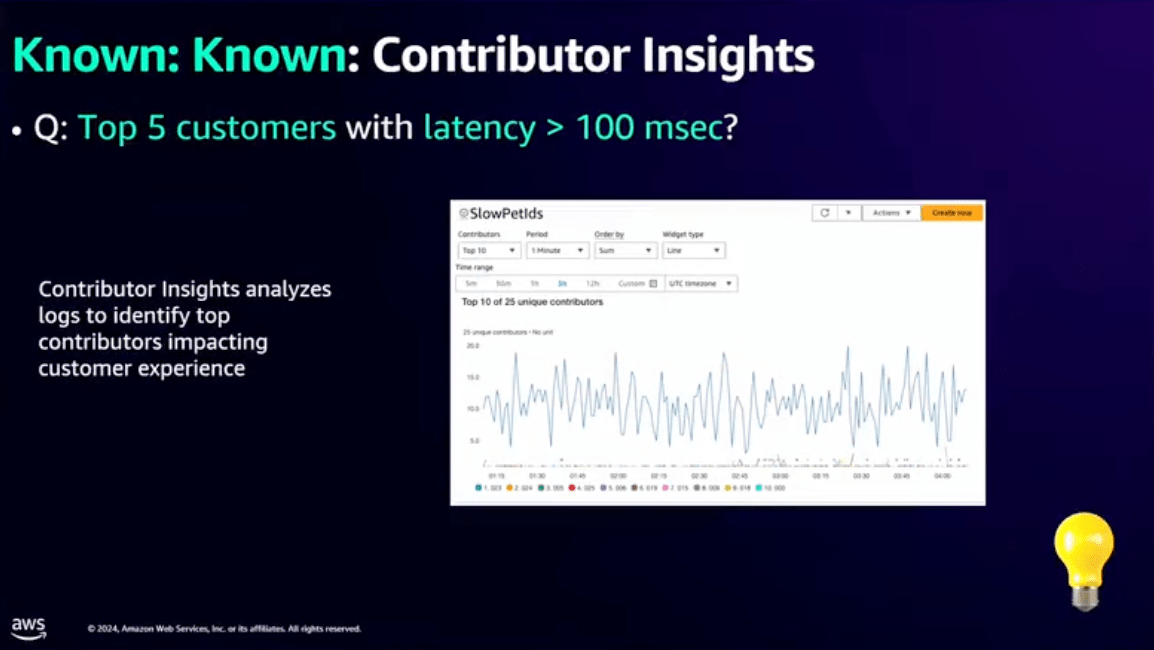
Contributor Insightsは特定のコントリビューター、つまり今回の場合だとWhatの部分を指定して、その情報をCloudWatch内で自動的に収集して分析してくれる機能です。
Contributor Insightsについては以下の記事が参考になります。
今回のケースでは100ms以上のレイテンシを指定して、トップNの値を簡単に把握することができます。
また、集計した値を簡単にダッシュボードで可視化したり、CloudWatch Alarmと連携してアラームを設定することも可能です。
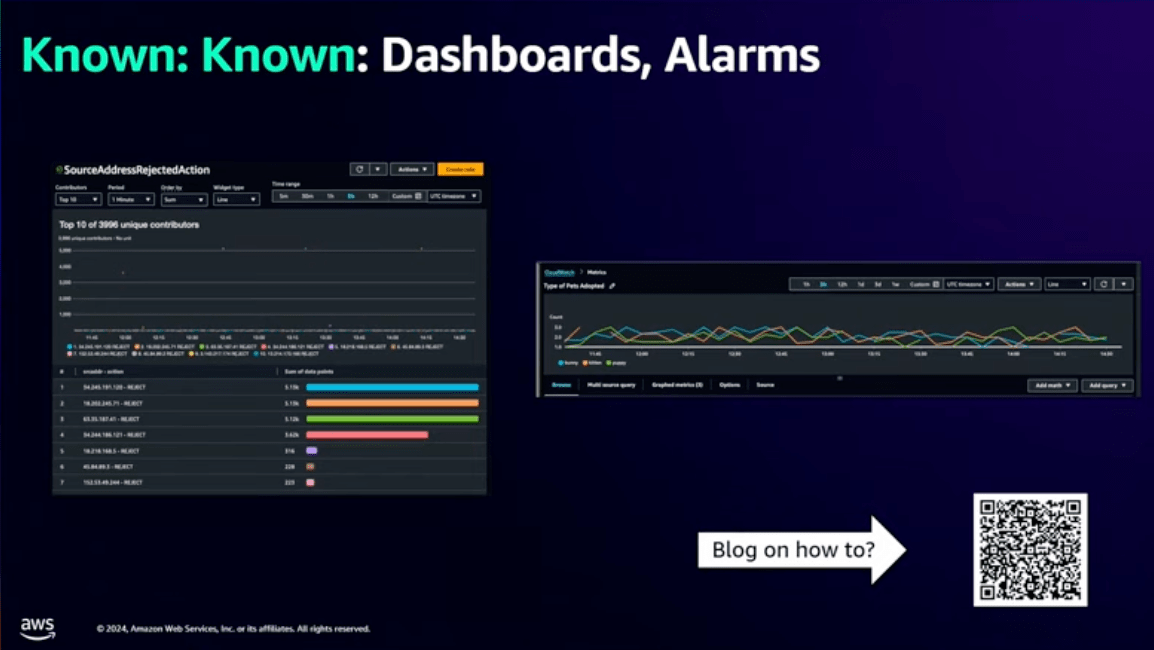
これは大量のデータに対してクエリしているわけではないため、余計なクエリコストがかかっているという訳でもありません。
また、ダッシュボードはデフォルトで用意されているものも多く、使い始めのハードルは低いようです。
こういった集計や可視化の仕組みがAWSのみで完結するのは素晴らしいですね。
上記のブログでも書かれていますが、Contributor Insightsはあまり深く分析する用途には向かず、今回のケースのように簡単にインサイトを得たい場合に利用するケースが多いように感じます。
例えば、トップ顧客やCPU使用率の高いコンピュータを特定するのには向いてそうですね。
新機能
Amazon CloudWatch と Amazon OpenSearch Service が統合
こちらは先日新機能としてリリースされたCloudWatchとAmazon OpenSearch Service間でZero-ETL統合されたという機能の紹介です。

以下はやってみたブログです。
この新機能により、ETLやクラスターの管理が不要で、すぐに使えるダッシュボードを作成することができます。
また、OpenSearchのPPLとSQLが使えるようになるので、私の個人的には苦手なCloudWatch Logs Insightsのクエリ言語を使わなくていいというのもメリットだと思います。
上記のブログでも書かれていますが、
これまでCloudWatch LogsのログをOpenSearchで検索するには、一度OpenSearchにデータを送信する必要がありました。
アップデートにより、Amazon CloudWatch Logsに対して直接クエリを実行でき、ダッシュボードも自動作成されるため、トラブルシューティングが簡単になりました。
Enhanced log analytics
こちらもリリースされたばかりの機能になります。

Enhanced log analyticsにより、今までロググループへのクエリは50個までという制限が、10,000個まで拡張され、プレフィックスを使用したログ検索も可能になりました。
また、ログのインデックス作成や、取り込み時のログ変換機能が追加されたことで、既存のメトリクスフィルタがさらに使いやすくなりました。
ログの変換では、JSONやGrokなどの形式をサポートしており、WAF, VPCフローログ, Apache, Nginxなどのテンプレートも用意されています。
ログの変換時はカスタムも可能で、ログからデータを抽出してコンテキストを追加することも可能です。
例えば、変換時にログにリージョンやロググループ名をキーとして追加することもできるようです。
この追加したキーを使って、メトリクスフィルタでフィルタリングすることもできそうですね。

Enhanced log analyticsのやってみたブログはこちらがおすすめです。
サーバー側でログの変換や、出力するログにデータを追加する必要がないので便利そうですね。
デモ
次に実際にコンソール画面を触りながらデモを行うセクションがあります。
こちらは動画を見ていただく方が分かりやすいと思うので、デモ開始の部分からのリンクを貼っておきます。
英語が分からなくても(私は全く分かりません)字幕をつければ、大体何をやっているか分かると思うので、興味がある方は是非見てみて下さい。
内容は、上記で説明した機能のデモを行っています。
Known:UnKnown
次に未知の情報ある場合です。
このパターンではコストは二の次で、より深いインサイトを得ることを目的とします。
最初にあげた例で
「変更を加えましたが、何か新しいログはありますか?」や
「このリクエストIDで何が起きていますか?」などの質問がありました。
これらのケースをどう解決するかみていきましょう。

解決に最も重要なのは事前準備を行うことです。
事前準備というのは例えば、ロググループの命名規則を整えることで検索が簡単になります。
他にも、検索しやすいようにログ取り込み時に変換を行っておくや、ログに構造を持たせておくということです。

質問1
先ほど例にあげた問題に対して、CloudWatchで変更後のログを確認できるツールが2つあります。
Live Tail
まずはLive Tail機能です。
こちらは2023年に発表された機能になります。
Live Tailはリアルタイムにログを確認できる機能です。
下の画像は実際にLive Tailでリアルタイムモニタリングを行っている画像です。

例えば、Lambdaで変更を加えたとき、変更による影響をリアルタイムに確認することができます。
また、今年はストリーミングCLIのサポートも追加されました。
Lambdaのコンソールにもネイティブ組み込まれています。
Log Insights
変更前と変更後を比較する方法としてLog Insightsで比較することもできます。
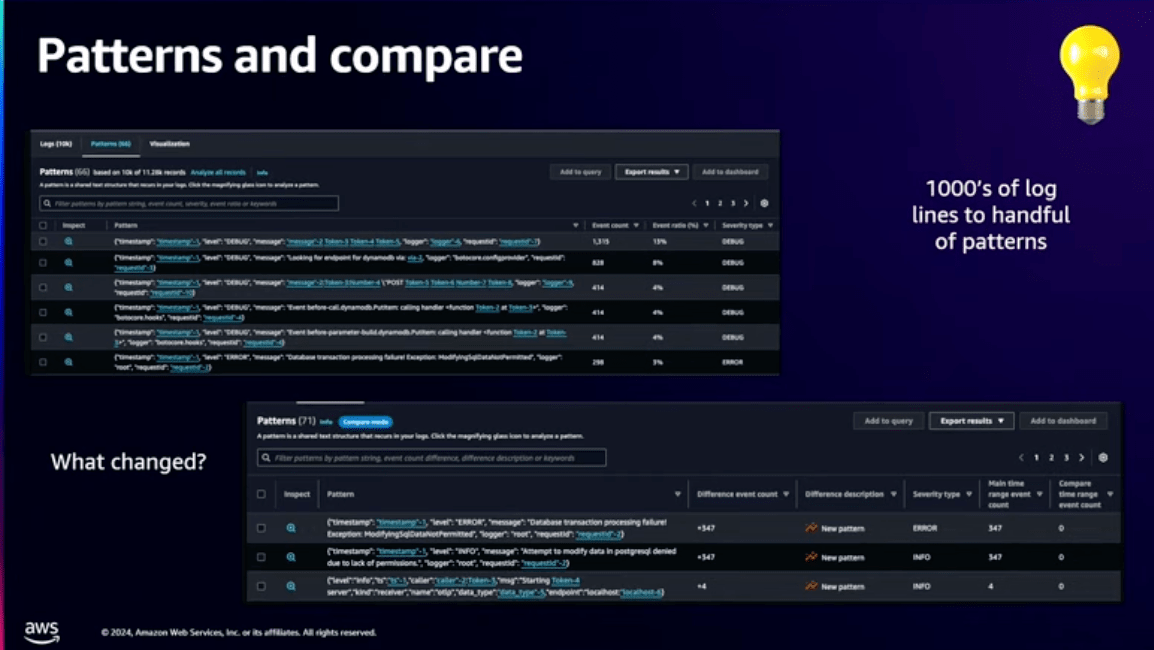
Log Insightsを使うと複数のクエリを実行して違いを探すよりも簡単に違いを見つけることができます。
比較機能ではログ内の変数を取り除いてログの構造を簡素化します。
何万件のログを分析しなくても、パターンを絞り込んで重要なエラーや例外のみを分析することができます。
ログの比較についてはこちらのブログが参考になります。
Anomaly Detection
Log Insightsでは手動でクエリを実行して結果を比較する必要があります。
そこで、このAnomaly Detectionを使うことで、自動でロググループから異常なログを検知してくれます。
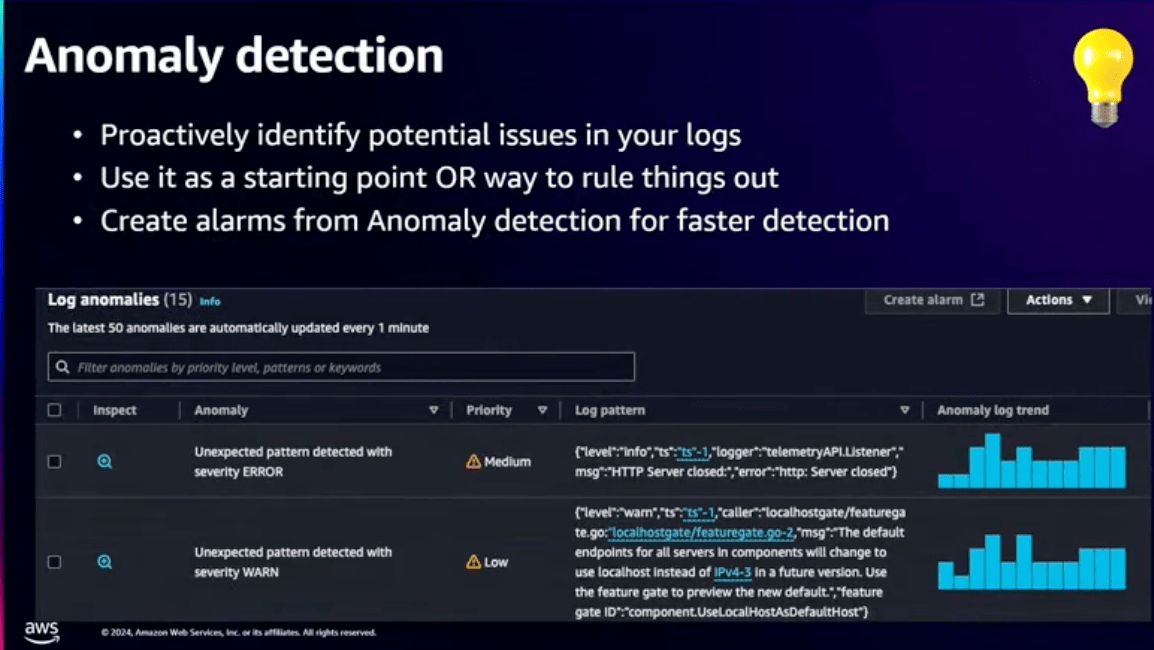
設定は特定のロググループのセットでAnomaly Detectionをオンにするだけで自動で監視が開始されます。
例えば、以前のパターンと比較して変動の大きいパターンを検知して、その異常度とどのような変動が起きているのかを表示してくれます。
Anomaly Detectionについてはこちらのやってみた記事が参考になります。
質問2
2つ目の質問の
「このリクエストIDで何が起きていますか?」
という質問を解決するには2つの問題があります。
1つ目に、リクエストID以外、何を見つければいいか分からないという問題
2つ目に、クロスアカウントの場合、膨大なロググループがあって何から始めればいいか分からない
という問題です。
上記の課題を解決するには、大量のログをスキャンする必要があります。
また、大量のログをスキャンするということはコストと時間がかかります。
この、すべてのログを検索したいけど、結果も早く欲しい。という2つの要素を同時に解決するのは難しいことです。
ここで、前述したEnhanced log analyticsが役立ちます。
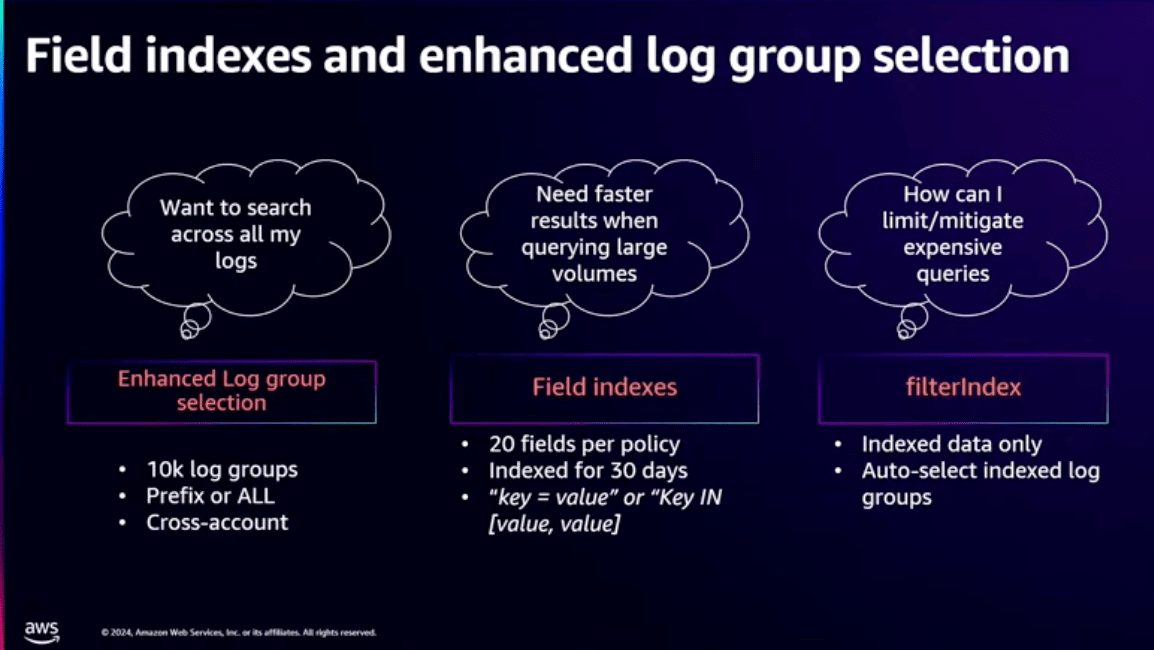
ログの一括検索
Enhanced log analyticsを利用することで、大量のロググループを一度に選択することが可能です。
これは個々のロググループを1つずつ見る必要がなくなるため、検索の効率が大幅に上がります。
また、検索にはロググループ内のプレフィックスを使ったり、アカウント内の一括検索も可能です。
もちろんそのためには、ロググループの命名規則は統一しておきたいところです。
検索速度向上
検索速度に関してはフィールドインデックスを導入したことにより、リクエストIDのような共通の属性を常に追跡することで、検索速度を上げています。
ちなみに、フィールドインデックスは1つのロググループにつき最大20個までフィールドを定義できるようです。
アカウントレベルでも設定可能で、ログが取り込まれると自動的にインデックス化されて30日間保持されます。
問題となるケース
ここで問題となるケースとして挙げられているのは、特定のロググループや時間の単位でリクエストIDをインデックス化していないが、すべてのロググループを検索したいというケースです。
確かに、このケースだとインデックス化されていないため、すべてのログをスキャンするのに時間がかかり、かつコストも増加しそうですね。
こんな時はどうしたらいいんでしょうか?
こんなケースでは新しいfilterIndexが役に立ちます。
filterIndexはインデックス化されたログのみを検索し、不要なスキャンを削減することができます。
デモ
次に実際にコンソール画面を触りながらデモを行うセクションがあります。
こちらは動画を見ていただく方が分かりやすいと思うので、デモ開始の部分からのリンクを貼っておきます。
まとめ

このセッションで学んで欲しいことはログを取得する際に、なぜそのログを取得するのか?ということを意識することで、ログの価値を最大化するという内容でした。
次に、最適なツールを使うということも言及していました。
ここでいうツールは、今回紹介したCloudWatchの各機能のことだと思います。
ログを活用する際には、無理をせずに、メトリクスフィルタやEMF、Contributor Insightsを利用して、なるべくシンプルに活用しましょう。
重要なのは、**「コスト削減」ではなく「価値の最大化」**です。
おわりに
実際に起こり得るケースを例にCloudWatchの機能を使って解決する方法を紹介するセッションでとても参考になりました。
機能があることは知っているけど、使ったことがない、使い所がいまいち分からないという機能が多かったですが、このセッションでなんとなくこういうケースで使うのか〜というのが参考になったので、同じようなトラブルに出会った際はぜひCloudWatchを使ってみたいと思います。
もちろん中には思ってるよりコストがかかるであろう機能などもあると思うので、使う前には利用費の確認は必須ですよ!









